
파이썬의 효과적인 메모리 재활용 방법 - Interning
References
제가 글을 쓰면서 참고했던 글입니다. 참조된 글과 다르게, 이 글은 Python 3.7 기준으로 설명되어 있습니다.
또한, 파이썬에서 꼭 상수만 interning 하는 것은 아닙니다. 웬만한 object에 대해서는 interning을 적용하고 있습니다. (숫자와 문자열도 object 이고요)
며칠 전 회사 Slack에 이런 질문이 올라왔습니다.
Python 3.7에서만 id가 다르네요. 원인이 뭘까요? 일반적인 문자열은 정상적으로 True가 나오지만
!가 있으면 결과가 달라지네요.>> a, b = "python!", "python!" >> a is b False
마침 저는 회사에 들어온 지 얼마 되지 않은 풋내기라 퇴근까지 할 일이 많지 않았고, 이내 저 질문에 답변을 해주어야겠다는 욕망에 사로잡혔습니다. 직감적으로 !이 들어가 있을 때는 동일한 값을 할당한다 하더라도 같은 메모리 공간을 참조하지 않도록 파이썬이 처리하고 있으리라 생각했지만, 이 생각을 뒷받침해주기 위해서는 파이썬이 정확히 어떤 식으로 문자열을, 혹은 더 나아가서 어떤 식으로 변수에 값을 저장하고 활용하는지에 대한 이해가 필요했습니다.
파이썬의 상수 재활용
파이썬은 특정 literal에 대해서는 값을 재활용 (= 동일한 메모리 공간을 재사용) 합니다. 이는 (대부분의) 파이썬 실제 구현체인 CPython 코드를 보면 알 수 있습니다. CPython/Objects/longobject.c 을 보면,
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
get_small_int(sdigit ival)
{
PyObject *v;
assert(-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS);
v = (PyObject *)&small_ints[ival + NSMALLNEGINTS];
Py_INCREF(v);
#ifdef COUNT_ALLOCS
if (ival >= 0)
_Py_quick_int_allocs++;
else
_Py_quick_neg_int_allocs++;
#endif
return v;
}
CHECK_SMALL_INT에서 -NSMALLNEGINTS <= ival < NSMALLPOSINTS 사이의 숫자인지 확인하고, 참이라면 내부적으로 저장하고 있는 small_ints 배열의 참조를 하나 증가시키고 그 값을 그대로 반환합니다. 즉, -5부터 256까지의 숫자는 내부적으로 재활용되고 있습니다.
숫자 뿐만 아니라 문자에 대해서도 이러한 작업을 수행하는데요. 이는 CPython/Objects/codeobject.c 의 다음 부분에서 확인할 수 있습니다.
intern_string_constants(PyObject *tuple)
{
int modified = 0;
Py_ssize_t i;
for (i = PyTuple_GET_SIZE(tuple); --i >= 0; ) {
PyObject *v = PyTuple_GET_ITEM(tuple, i);
if (PyUnicode_CheckExact(v)) {
if (PyUnicode_READY(v) == -1) {
PyErr_Clear();
continue;
}
if (all_name_chars(v)) { // all_name_chars: true iff s matches [a-zA-Z0-9_]
PyObject *w = v;
PyUnicode_InternInPlace(&v);
if (w != v) {
PyTuple_SET_ITEM(tuple, i, v);
modified = 1;
}
}
}
}
all_name_chars의 조건에 맞는 char라면 재활용할 수 있도록 하는 코드가 내부적으로 들어있군요. 벌써 정답에 근접한 것 같은 느낌이 드는데요? 역시 모든 답은 코드에 있었습니다.
참고로, 이렇게 자주 사용되는 상수들에 대해 여러 변수가 값을 참조할 수 있도록 내부적으로 저장하는 행위를 intern 이라고 합니다. 비슷한 일을 하는 내장 함수도 있습니다.
결론
파이썬은
-5 ~ 256범위에 해당하는 숫자와,[a-zA-Z0-9_]에 해당하는 char에 대해서는 내부적으로 intern 하고 있습니다.
그래서 어떤 식으로 재활용이 되는 건가요?
다음 예제를 보면, (참고: 64비트 환경입니다.)
>>> a = 1
>>> b = 1
>>> hex(id(a))
'0x106694c50'
>>> hex(id(b))
'0x106694c50'
>>> hex(id(1))
'0x106694c50'
두 개의 변수 a, b에 각각 1이라는 값을 할당해주었는데, 변수의 주소를 확인해보면 상수 1의 주소로 참조되고 있음을 알 수 있습니다. 아래 그림처럼요!
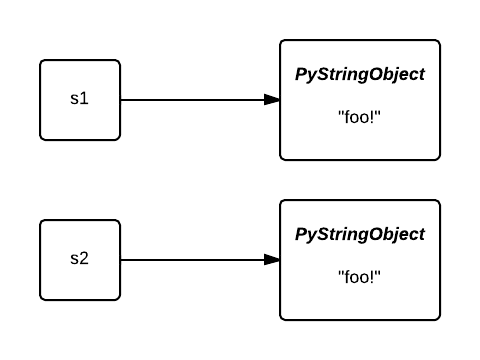
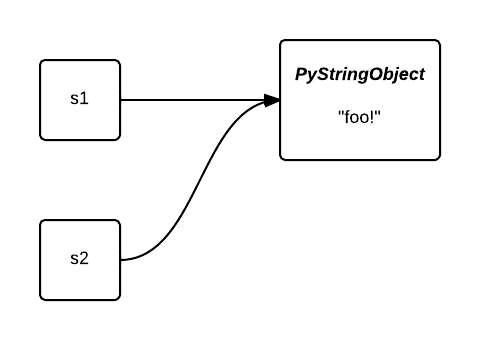
정말 이게 끝일까요?
아래 코드를 보면…
>>> a = 257; b = 257
>>> hex(id(a))
'0x10bfc2fb0'
>>> hex(id(b))
'0x10bfc2fb0'
분명 범위를 벗어나는데도 불구하고 두 변수가 같은 값을 참조하고 있습니다. 우리가 무엇을 놓친 걸까요?
컴파일 시점 (compile time) 에 추가적인 재활용이 일어난다
파이썬은 인터프리터 언어이지만, 파이썬 인터프리터가 실제로 해석하는 값은 코드가 아닌 컴파일된 바이트 코드입니다. (무슨 말인지 모르시겠다구요?) 즉, 유저의 코드를 바이트 코드로 변환하는 시점에서 전체 프로그램에 대한 더 많은 정보를 알 수 있게 됩니다. 다시 아까의 CPython 코드를 참조해볼까요? 이번에도 CPython/Objects/codeobject.c 입니다.
PyCodeObject *
PyCode_New(int argcount, int kwonlyargcount,
int nlocals, int stacksize, int flags,
PyObject *code, PyObject *consts, PyObject *names,
PyObject *varnames, PyObject *freevars, PyObject *cellvars,
PyObject *filename, PyObject *name, int firstlineno,
PyObject *lnotab)
{
... 생략 ...
intern_strings(names);
intern_strings(varnames);
intern_strings(freevars);
intern_strings(cellvars);
intern_string_constants(consts);
}
CPython에서 Code object를 생성할 때, consts와 같은 추가적인 정보들을 참고하여 다시 한 번 intern 해주는 코드가 들어있습니다. 즉, 범위에 해당하지 않더라도 코드에서 사용하는 상수와 그 외에도 위에 나와있는 많은 것들 - names, varnames 등이 intern 되는 거죠.
특히 intern이 컴파일 시점에 일어난다는 사실에 주목할 필요가 있는데요. 이것때문에 REPL에서 실행할 때와 .py 로 된 코드를 실행할 때의 결과가 다를 수 있습니다. 아래 예제를 한 번 볼까요?
>>> a = "h!"
>>> b = "h!"
>>> hex(id(a)), hex(id(b))
('0x10d0f3880', '0x10d0f38b8')
>>> a = "h!"; b = "h!"
>>> hex(id(a)), hex(id(b))
('0x10d0f3928', '0x10d0f3928')
첫 번째 결과는 a, b에 값을 할당하는 코드를 각각 실행합니다. REPL에서는 한 줄씩 읽어서 그걸 바이트 코드로 변환하고 해석하기 때문에, a, b에 똑같은 값을 할당하라고 해도 컴파일 시점이 달라 두 변수가 다른 주소의 값을 가지게 됩니다. 반면에, 두 번째 결과는 a, b에 값을 할당하는 코드가 한 번에 실행됩니다. 그리하여 "h!"가 여러 번 참조되는 상수라는 것을 컴파일 시 알 수 있고, 같은 주소를 참조하게 만들어 재활용합니다. 이런 차이 때문에, REPL에서 실행한 결과를 볼 때는 주의가 필요합니다. 평소에 우리가 실행하던 코드의 결과와 다를 수 있으니까요.
또한, 아래와 같은 코드에서 s2는 intern 되지 않을 수 있습니다. 컴파일 시점에서는 s2가 foo가 된다는 사실을 알 수 없기 때문이죠.
s1 = 'foo'
s2 = ''.join(['f', 'o', 'o'])
결론
범위 바깥의 값도 컴파일 시점에서 intern 될 수 있습니다. 특히, 여러 번 참조되는 상수 등이 그렇습니다.
아직도 알쏭달쏭
그럼 아래 코드는 어떻게 설명해야 할까요?
>>> 'foo' + 'bar' is 'foobar'
True
컴파일러가 'foo' + 'bar'는 'foobar' 라는 것을 알아낸 듯 싶습니다. 이 결과만 보면 runtime에도 intern이 일어나는 것처럼 보이는데요. 사실 이 결과를 설명하기 위해선 컴파일 시점에 일어나는 마법에 대해 조금은 알아야 할 필요가 있습니다.
컴파일러 최적화
많은 컴파일러들이 사용자가 짠 코드를 곧이곧대로 해석하지 않고, 최적화할 수 있는 부분을 찾아내어 더 좋은 코드, 더 짧은 명령어로 바꿔줍니다. 본 글에서 다루려는 주제가 컴파일러 최적화에 대한 것은 아니므로, 위의 예제와 관련된 파이썬의 컴파일러 최적화 방법만 잠깐 언급하고 넘어가도록 하겠습니다. 파이썬은 Peephole이라는 최적화 구현체를 통해 여러 가지 코드 최적화를 컴파일 시점에 적용하고 있는데요.
그 중 Constant Folding 이라는 최적화 기법은, 'foo' + bar'와 같은 간단한 연산을 바이트 코드단에서 미리 계산하는 방식의 최적화 기법입니다. 더하기가 포함된 위의 코드를 바이트 코드로 변환하면 원래는 아래와 같이 되어야 하지만,
2 0 LOAD_CONST 1 ('foo')
3 LOAD_CONST 2 ('bar')
6 BINARY_ADD
실제로 실행해 보면 다음과 같은 결과를 얻을 수 있습니다.
>>> dis.dis(compile("foo" + "bar", '<stdin>', 'single'))
1 0 LOAD_NAME 0 (foobar)
2 PRINT_EXPR
4 LOAD_CONST 0 (None)
6 RETURN_VALUE
똑똑한 컴파일러가 명령어를 줄였네요. 그렇기에, foo + bar와 foobar는 intern 될 수 있었습니다.
첫 질문에 대한 답변
드디어, 본문 서두에 나온 질문에 대한 답변을 할 수 있게 된 것 같습니다. 위에서 알아낸 결과를 바탕으로 답변해보자면, !가 들어가서 intern이 되지 않아야 하지만, 같은 줄에 선언했기 때문에 컴파일 시점에 intern이 되어 a is b의 결과는 True가 돼야 할 것입니다. 일단, 아래의 코드가 파이썬 3.7에서만 다르다고 했으니, 파이썬 2.7과 결과를 비교해보기로 하였습니다.
- 파이썬 2.7.10 (Apple LLVM)
>>> a, b = "python!", "python!" >>> a is b True - 파이썬 3.7.1 (Clang)
>>> a, b = "python!", "python!" >>> a is b False
확실히 다르군요. 여러 버전에서 추가 실험을 해본 결과, 유독 파이썬 3.7에서만 False라는 결과가 나왔습니다. 즉, 3.7 이전까지는 intern 로직이 위의 결과에 대해 적용되었지만 3.7부터는 어떠한 이유로 인해 intern이 되지 않는 걸로 보이네요.
내부적으로 무슨 일이 일어나고 있는지 확인하기 위해, 바이트 코드를 살펴보도록 하겠습니다. 위에서도 이미 활용했지만, dis라는 패키지를 이용하면 파이썬 코드를 쉽게 바이트 코드로 변환할 수 있습니다. 일종의 파이썬 disassembler인 셈이죠.
- 파이썬 2.7.10 (Apple LLVM)
>>> dis.dis(compile("a, b = 'python!', 'python!'", "<stdin>", "single")) 1 0 LOAD_CONST 2 (('python!', 'python!')) 3 UNPACK_SEQUENCE 2 6 STORE_NAME 0 (a) 9 STORE_NAME 1 (b) 12 LOAD_CONST 1 (None) 15 RETURN_VALUE - 파이썬 3.7.1 (Clang)
>>> dis.dis(compile("a, b = 'python!', 'python!'", "<stdin>", "single")) 1 0 LOAD_CONST 0 (('python!', 'python!')) 2 UNPACK_SEQUENCE 2 4 STORE_NAME 0 (a) 6 STORE_NAME 1 (b) 8 LOAD_CONST 1 (None) 10 RETURN_VALUE참고: 명령어 옆 숫자가 다른 이유는 파이썬 2에서는 명령어를 가리키는 byte index가 3의 배수이고, 3에서는 2의 배수이기 때문입니다.
바이트 코드를 살펴보면, a, b = "python!", "python!"과 같이 호출했지만 내부적으로는 tuple이 만들어지고, UNPACK_SEQUENCE를 통해 각 변수에 할당되는 모습을 볼 수 있는데요. 잘 살펴보면, LOAD_CONST 옆의 숫자가 2 -> 0으로 줄어들었습니다. 이는 tuple을 생성하기 위해 LOAD_CONST가 원래는 2개의 인자를 받고 있었는데, 인자를 받지 않고도 tuple을 생성할 수 있도록 변했다는 이야기입니다. 인자 개수가 줄어든걸로 보아 tuple 생성 단계에서 최적화가 이루어졌지만, 이로 인한 버그때문에 string이 intern되지 않는 거라는 생각이 들었습니다.
어쩌다보니 파이썬 최신 버전 (3.7.1) 의 버그를 발견하게 되었네요! 기쁜 마음으로 파이썬 공식 저장소에 bug report를 만들러 가면 되겠습니다.
파이썬 최신 버전의 버그 발견
최초의 버그 발견이었다면 좋았겠지만, Python bug tracker를 찾아 들어가보니 제가 발견한 내용에 대해 이미 2018년 7월에 버그 제보가 완료된 상태이고, 11월에 PR 또한 merge되어 파이썬 3.8에 릴리즈될 예정이라고 합니다. 파이썬같은 거대한 프로젝트에 첫 issue와 더불어 어쩌면 PR까지? 라는 꿈에 부풀어 버선발로 달려가보았는데, 역시 사용자가 많은 파이썬답게 출시 1개월만에 버그가 제보되었네요. 여기서 자세한 내용을 확인하실 수 있습니다.
그리고 이러한 버그 덕에, intern을 heavy하게 사용하고 있는 프로그램에서는 급격한 성능 저하가 발생할 수 있는데요. 특히 corpus를 만드는 작업처럼 중복된 문자열이 대규모로 들어오는 경우에 intern을 이용하여 상당한 공간과 시간을 절약할 수 있지만, 그러한 프로그램을 사용하고 계시다면 파이썬 3.7은 건너뛰시고 3.8로 바로 넘어가셔야 하겠네요. 한 눈에 들어오는 성능 비교를 위해, interned string과 non-interned string의 비교 벤치마크를 아래와 같이 첨부하겠습니다.
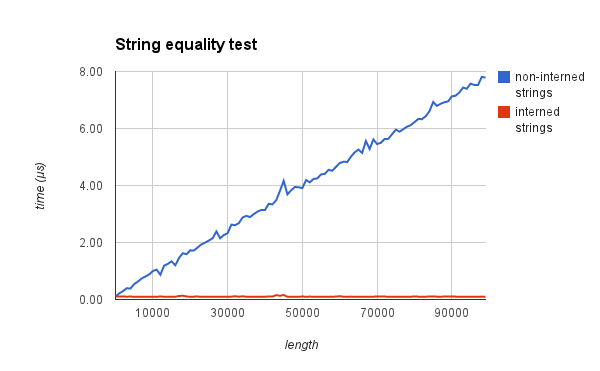
O(1) vs O(N)의 싸움입니다.
단순 포인터 비교 vs byte 비교를 length만큼
결론

결국 질문에 대한 답변은 하지 못한채, 버그라는 결론을 내리고 마쳐야 했습니다. 사실 저도 파이썬 구현체의 코드를 직접 타고 들어가서 본 적은 처음이어서, 답변을 하는 과정에서 새로운 것을 많이 배우고 익힐 수 있었기 때문에 결론이 제대로 나오지 않았어도 유익한 시간이 되었던 것 같습니다. 이러한 경험 덕에, 앞으로 파이썬이 미덥지 못할 때마다 코드를 직접 보고 혼내줘야겠다는 생각이 들었습니다.
이와 별개로, 처음에 저 질문을 들었을 때 잠깐 찾아보고 슬랙에 바로 답글을 남겼었는데요. 그 답변이 얼마나 허접한 수준의 답변이었는지 지금에서야 깨닫게 됐습니다. 앞으로는 질문에 답을 남길 때 좀 더 신중하게 생각해봐야겠습니다.
Comments